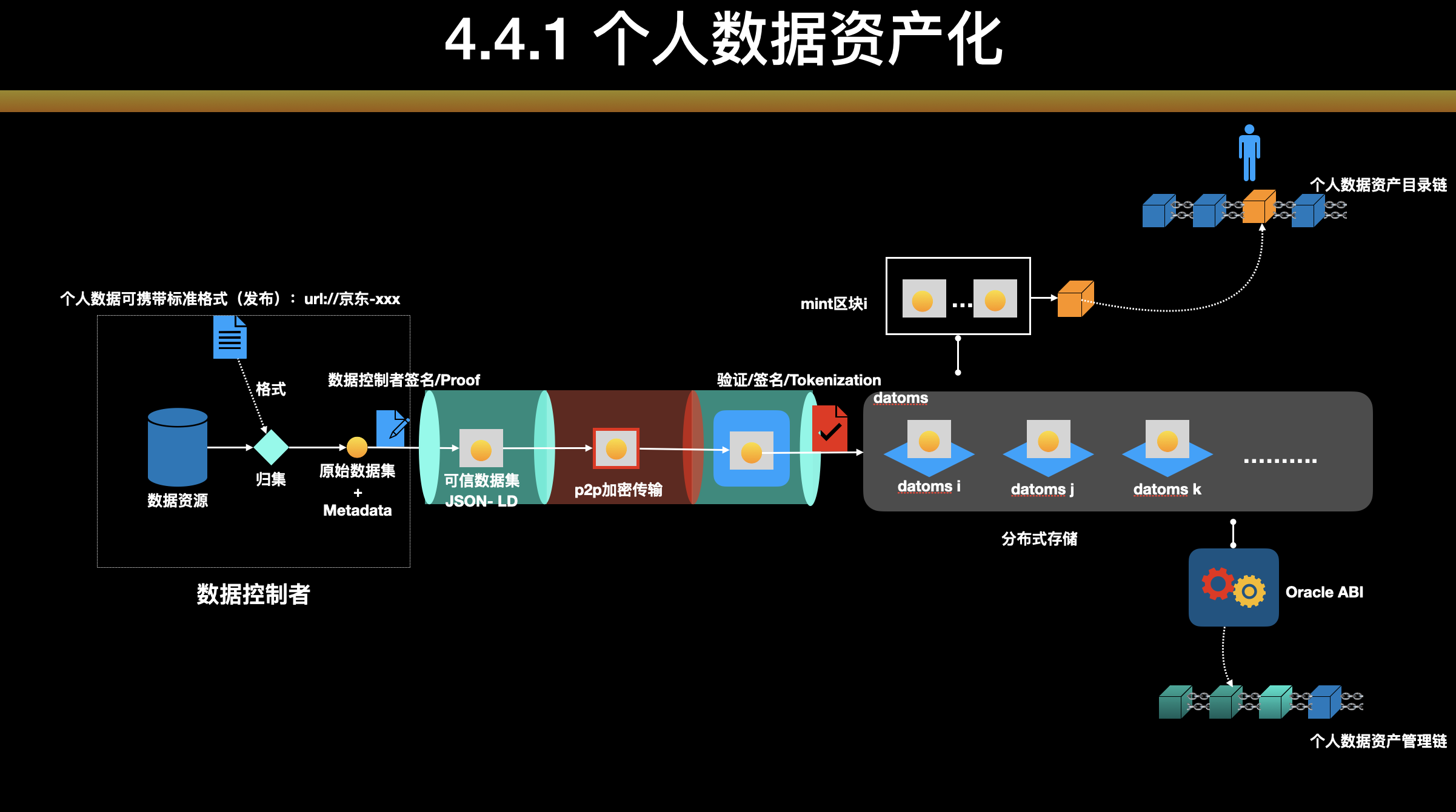
数据层概述
PeopleData的数据层(Data Layer)是一个多层次的架构设计,旨在解决个人数据开发利用中的"安全、开放和隐私"三重利益之间的不可能三角困境。
DL0层:数据生产层
负责个人数据的原始生成和采集,是整个数据价值链的起点。
DL1层:个人数据主权基础设施
实现个人数据资产的保护、治理和管理,确保数据主权。
DL2层:数据资本形成基础设施
构建自治、动态、虚拟和分布式的个人数据合作组织,实现数据价值的释放。
DL3层:价值生态层
基于底层基础设施,构建多样化的场景应用,实现数据价值的多元化开发利用。

PeopleData数据层结构示意图